
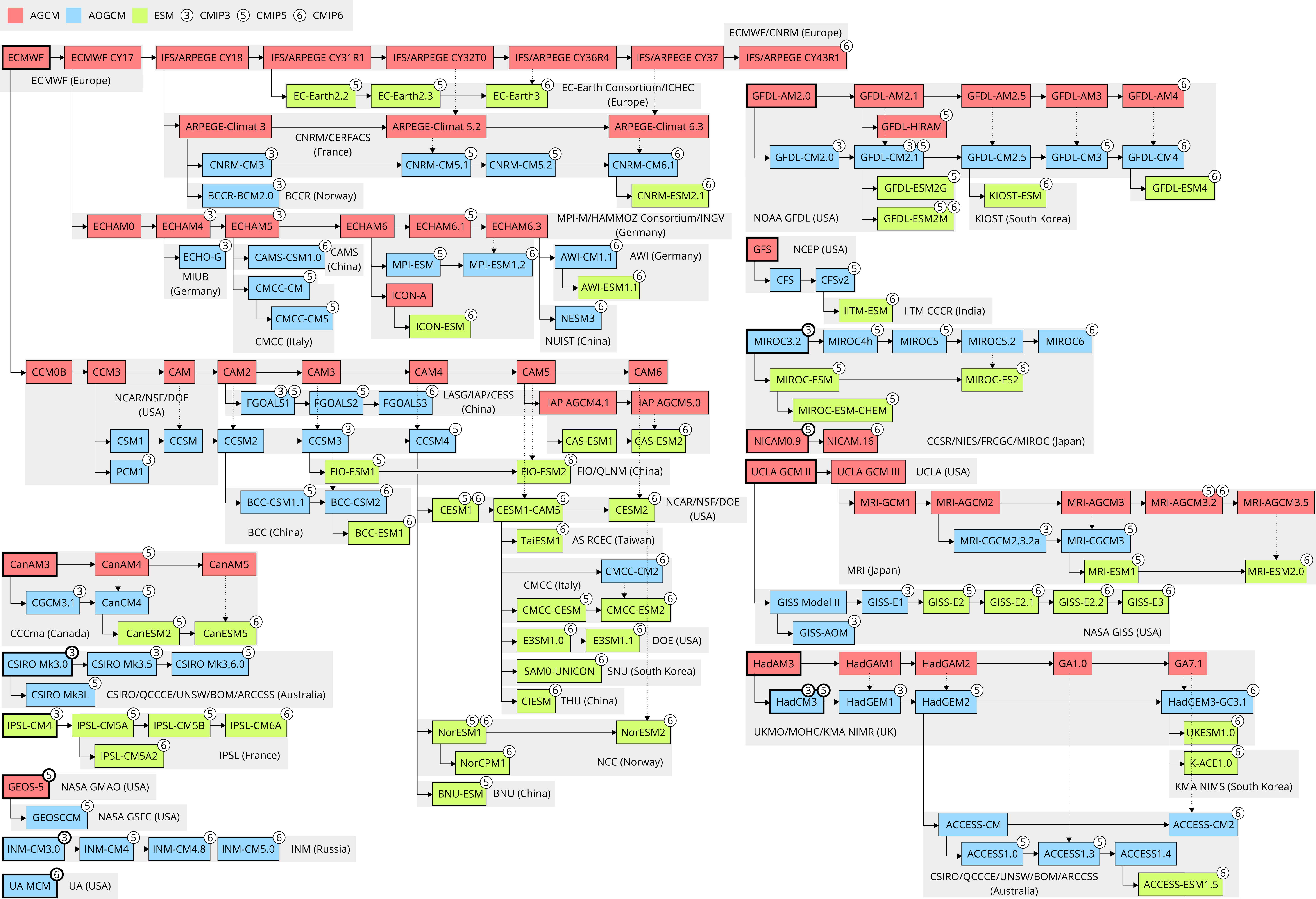
Almost ever since the advent of computers, climate models have been developed to simulate the Earth’s climate. First, in order to scientifically understand the climate system, and later to also understand climate change and predict future climate depending on greenhouse gas and aerosol emissions. Early climate models simulated only the atmosphere, later models added the ocean, and modern climate models, called Earth system models, also simulate the cryosphere, biosphere and chemical processes in the atmosphere and ocean. Many countries started developing one or more state-funded climate models through research institutes. Over time, hundreds of such models have been developed, often borrowing computer code from one another. The immense complexity and size of the code often makes starting a new model from scratch prohibitively expensive and time-consuming. This has lead to a maze of model relationships, which until now has not been properly studied.
Many climate studies today rely on results coming from a set of models, called a model ensemble, for example by averaging the results of multiple models. This serves as protection from deficiencies of any single model, but also allows scientists to quantify the uncertainty in their results and capture a greater amount of variability due to our uncertainty about climate processes and how to simulate them on a computer, with each model representing them differently. Including multiple models which share any code in such an ensemble then leads to a certain amount of dependency, and certain groups of models sharing substantial amounts of code can be over-represented in the ensemble. Ideally, this should be known and quantified, and over-representing models should be avoided.
In our study we constructed a code genealogy, or a ‘family tree’, of 167 atmosphere-only, atmosphere–ocean, and Earth system models spanning several decades, including all models participating in the Coupled Model Intercomparison Project (CMIP) phases 3, 5 and 6. We have found that all of the studied models trace their history back to about 14 ancestral models, forming 14 model families. Within each family, models often tend to produce similar results such as global temperature, so-called climate feedbacks and sensitivity of temperature to greenhouse gas concentrations. We have found that only 3 model families together comprise about 70% of all models in the latest CMIP phase.
We propose a statistical weighting which takes into account the code relationships between models, so that for example more balanced averages can be calculated from model ensembles. This is in contrast to a simple ‘model democracy’, where every model in an ensemble is given the same statistical weight, as in one model one vote, which would be only truly applicable if all models were completely independent.
When constructing the genealogy, our focus was on the component of models simulating the atmosphere, but a similar genealogy could be constructed with a focus on the ocean-simulating component. This was motivated by the fact that currently cloud processes are the leading source of uncertainty in future climate projections.
The projected sensitivity of temperature to greenhouse gases has on average increased in the latest generation of CMIP models. Our results contribute to explaining a part of this increase. Models in families with high sensitivity have proliferated more in the latest phase of CMIP compared to other model families, and thus have a greater weight in the overall result, even though they are often closely related. Our proposed weighting, accounting for the dependencies, reduces the difference between the latest and the previous generation of CMIP models.
Future research could extend our analysis to the ocean component, quantify the strength of code relationships between the models, or look at how the identified model families differ in their simulation of different aspects of the climate system. Overall, this could help to explain why climate models do not always agree on their results, and thus reduce our uncertainty in future climate projections.
Our work was done at the Department of Meteorology and Bolin Centre for Climate Research at Stockholm University, and funded by the EU projects FORCeS and NextGEMS and the Swedish e-Science Research Centre. The results have been published in the Journal of Advances in Modeling Earth Systems (https://doi.org/10.1029/2022MS003588).
