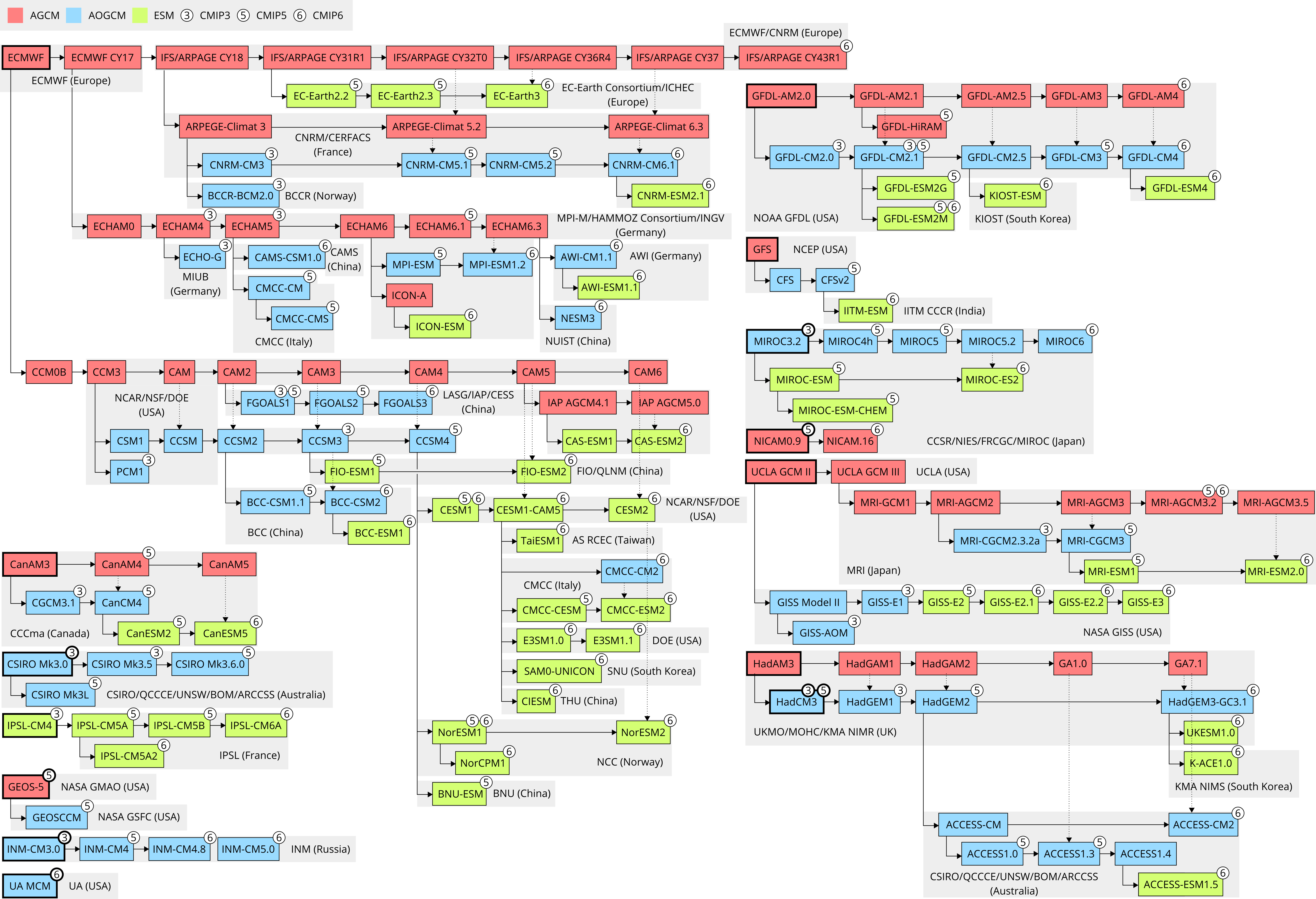
Contemporary general circulation models and Earth system models are developed by a large group of modelling centres internationally. They use a broad range of implementations of climate dynamics and physical parametrisations, allowing for structural (code) uncertainty to be partially quantified with multi-model ensembles (MMEs). However, many models in the MMEs of the Climate Model Intercomparison Project (CMIP) have a common development history due to the widespread practice of sharing of code and parametrisations within and between modelling centres. This makes results from different models statistically dependent, potentially introducing biases in MME statistics. This situation became more pronounced in CMIP6 compared to CMIP5 due to the proliferation of model runs contributed by the same model, and due to the fact that several models predict much higher effective climate sensitivity (ECS) than multiple evidence assessments such as the Intergovernmental Panel on Climate Change Sixth Assessment Report, and this means that some MME statistics differ from multiple evidence estimates. Previous research investigating effects of model inter-dependence has focused on model output and code dependence, but model code genealogy of CMIP models has not been fully analysed. We present a full reconstruction of CMIP3, CMIP5 and CMIP6 model code genealogy based on available literature and online resources, with a focus on inheritance in the atmospheric component and atmospheric physical parametrisations. We developed a ‘fair’ model code weighting method based on the model code genealogy for the purpose of analysing the impact of such weighting on MME means. We assess the implications of such weighting on ECS, climate feedbacks, forcing and global mean near-surface air temperature, as well as simpler weighting methods based on model family, institute and country in CMIP5 and CMIP6. In some cases the impact is found to be substantial and can partially reconcile the differences in MME means between CMIP5 and CMIP6. We show that some model families have a propensity to be relatively warm or cold in the main CMIP5 and CMIP6 experiments. Our method is complementary to the existing methods based on model output clustering. The presented results can help in understanding of structural dependencies between CMIP models, and the proposed code and family weighting methods can be used in MME assessments to ameliorate model structure sampling biases.
Poster
Climate model code genealogy and its relation to sensitivity and feedbacks

Peter Kuma1, Frida A.-M. Bender1, Aiden R. Jönsson1
1Department of Meteorology (MISU), Stockholm University, Stockholm, Sweden
Abstract
- Conference:
- FORCeS Annual Meeting, Oslo, Norway, 14 September 2022
- Archive:
- Zenodo
- DOI:
- 10.5281/zenodo.7071718
- Published:
- 14 September 2022
- License:
- Open access / Creative Commons Attribution 4.0 (CC BY 4.0)
BibTeX:
@misc{kuma2022,
year={2022},
note={FORCeS Annual Meeting, Oslo, Norway, 14 September 2022},
doi={10.5281/zenodo.7071718},
url={https://doi.org/10.5281/zenodo.7071718},
author={Kuma, Peter and Bender, Frida A.-M. and J{\"o}nsson, Aiden R.},
title={Climate model code genealogy and its relation to sensitivity and feedbacks}
}
Document
